728x90
반응형
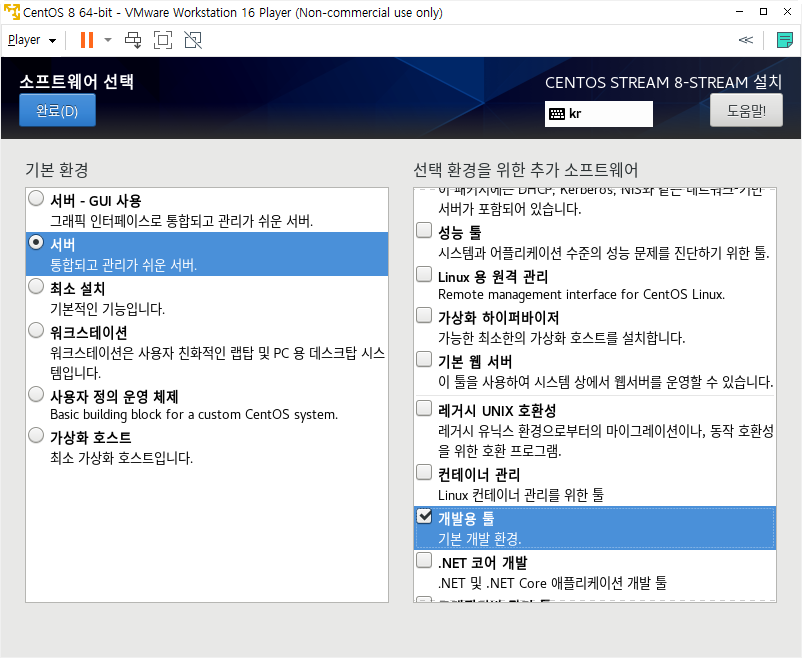
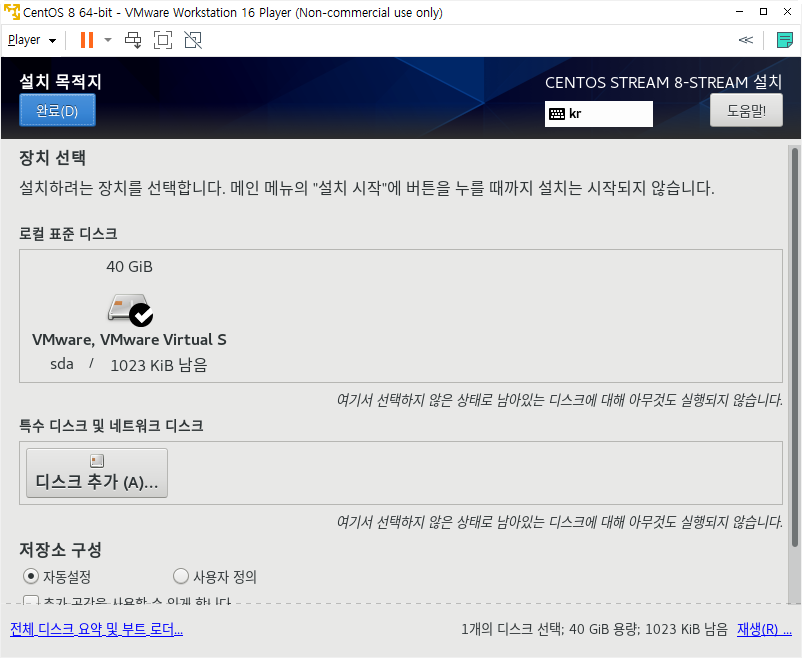
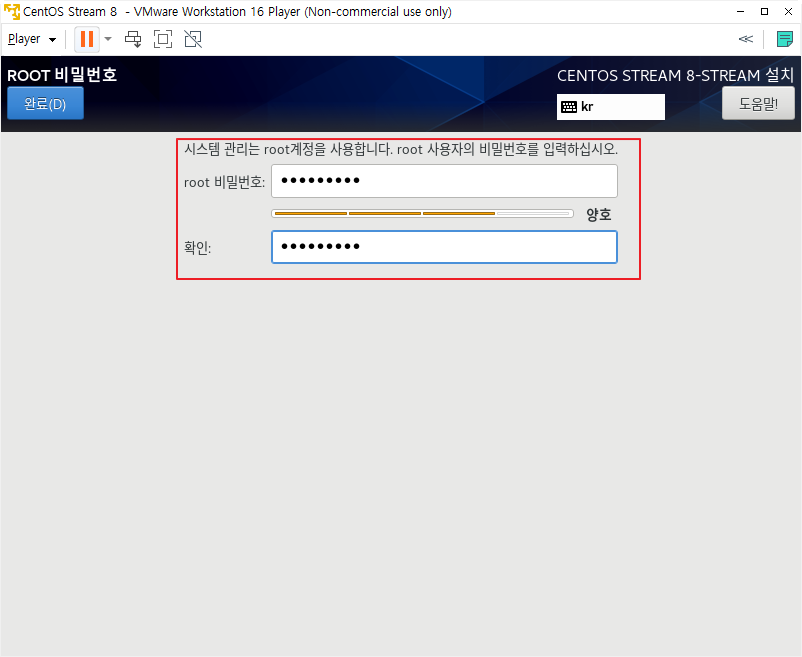
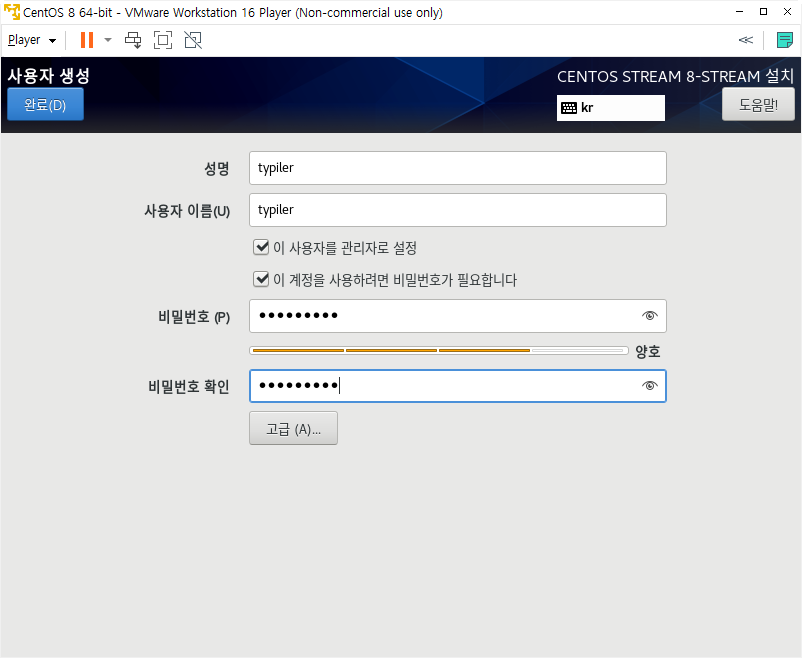
세그먼트 트리를 이용하여 구간의 합을 빨리 찾는 문제를 설명하도록 하겠습니다. 이번 포스팅은 영상을 찍어봤는데, 처음이라 자연스럽지 못하지만 나름 열심히 설명하려 노력했습니다. 어색하더라도 양해해 주십시오.
이론설명
초기설정구현

public static int init(int node, int start, int end) {
if (start == end) {
tree[node] = numbers[start];
} else {
int left = init(node*2, start, (start+end)/2);
int right = init(node*2+1, (start+end)/2+1, end);
tree[node] = left+right;
}
return tree[node];
}
구간합 찾기 구현
public static int query(int node, int start, int end, int a, int b) {
if (a > end || b < start) {
return 0;
}
if (a <= start && end <= b) {
return tree[node];
}
int left = query(node*2, start, (start+end)/2, a, b);
int right = query(node*2+1, (start+end)/2+1, end, a, b);
return left + right;
}
전체코드
import java.io.*;
import java.util.StringTokenizer;
public class Rsq {
static int[] numbers;
static int[][] questions;
static int[] tree;
public static int init(int node, int start, int end) {
if (start == end) {
tree[node] = numbers[start];
} else {
int left = init(node*2, start, (start+end)/2);
int right = init(node*2+1, (start+end)/2+1, end);
tree[node] = left+right;
}
return tree[node];
}
public static int query(int node, int start, int end, int a, int b) {
if (a > end || b < start) {
return 0;
}
if (a <= start && end <= b) {
return tree[node];
}
int left = query(node*2, start, (start+end)/2, a, b);
int right = query(node*2+1, (start+end)/2+1, end, a, b);
return left + right;
}
public static void main(String[] args) throws IOException {
System.setIn(new FileInputStream("input\\rsq.txt"));
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
numbers = new int[N];
questions = new int[M][2];
tree = new int[N*4];
st = new StringTokenizer(br.readLine());
for (int i=0; i<N; i++) {
numbers[i] = Integer.parseInt(st.nextToken());
}
for (int i=0; i<M; i++) {
st = new StringTokenizer(br.readLine());
questions[i][0] = Integer.parseInt(st.nextToken());
questions[i][1] = Integer.parseInt(st.nextToken());
}
br.close();
init(1, 0, N-1);
for (int i=0; i<tree.length; i++) {
System.out.println("tree[" + i + "] : " + tree[i]);
}
for (int i=0; i<M; i++) {
bw.write(query(1, 0, N-1, questions[i][0]-1, questions[i][1]-1)+"\n");
}
bw.flush();
bw.close();
}
}[input : input\rsq.txt]
5 3
5 4 3 2 1
1 3
2 4
5 5
[output]
12
9
1
728x90
반응형