맹목적 탐색방법의 하나로 탐색트리의 최근에 첨가된 노드를 선택하고, 이 노드에 적용 가능한 동작자 중 하나를 적용하여 트리에 다음 수준(level)의 한 개의 자식노드를 첨가하며, 첨가된 자식 노드가 목표노드일 때까지 앞의 자식 노드의 첨가 과정을 반복해 가는 방식입니다.
장점
단지 현 경로상의 노드들만을 기억하면 되므로 저장공간의 수요가 비교적 적다.
목표노드가 깊은 단계에 있을 경우 해를 빨리 구할 수 있다.
단점
해가 없는 경로에 깊이 빠질 가능성이 있다. 따라서 실제의 경우 미리 지정한 임의의 깊이까지만 탐색하고 목표노드를 발견하지 못하면 다음의 경로를 따라 탐색하는 방법이 유용할 수 있다.
얻어진 해가 최단 경로가 된다는 보장이 없다. 이는 목표에 이르는 경로가 다수인 문제에 대해 깊이우선 탐색은 해에 다다르면 탐색을 끝내버리므로, 이때 얻어진 해는 최적이 아닐 수 있다는 의미이다.
세그먼트 트리를 이용하여 구간의 합을 빨리 찾는 문제를 설명하도록 하겠습니다. 이번 포스팅은 영상을 찍어봤는데, 처음이라 자연스럽지 못하지만 나름 열심히 설명하려 노력했습니다. 어색하더라도 양해해 주십시오.
이론설명
초기설정구현
public static int init(int node, int start, int end) {
if (start == end) {
tree[node] = numbers[start];
} else {
int left = init(node*2, start, (start+end)/2);
int right = init(node*2+1, (start+end)/2+1, end);
tree[node] = left+right;
}
return tree[node];
}
구간합 찾기 구현
public static int query(int node, int start, int end, int a, int b) {
if (a > end || b < start) {
return 0;
}
if (a <= start && end <= b) {
return tree[node];
}
int left = query(node*2, start, (start+end)/2, a, b);
int right = query(node*2+1, (start+end)/2+1, end, a, b);
return left + right;
}
전체코드
import java.io.*;
import java.util.StringTokenizer;
public class Rsq {
static int[] numbers;
static int[][] questions;
static int[] tree;
public static int init(int node, int start, int end) {
if (start == end) {
tree[node] = numbers[start];
} else {
int left = init(node*2, start, (start+end)/2);
int right = init(node*2+1, (start+end)/2+1, end);
tree[node] = left+right;
}
return tree[node];
}
public static int query(int node, int start, int end, int a, int b) {
if (a > end || b < start) {
return 0;
}
if (a <= start && end <= b) {
return tree[node];
}
int left = query(node*2, start, (start+end)/2, a, b);
int right = query(node*2+1, (start+end)/2+1, end, a, b);
return left + right;
}
public static void main(String[] args) throws IOException {
System.setIn(new FileInputStream("input\\rsq.txt"));
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
numbers = new int[N];
questions = new int[M][2];
tree = new int[N*4];
st = new StringTokenizer(br.readLine());
for (int i=0; i<N; i++) {
numbers[i] = Integer.parseInt(st.nextToken());
}
for (int i=0; i<M; i++) {
st = new StringTokenizer(br.readLine());
questions[i][0] = Integer.parseInt(st.nextToken());
questions[i][1] = Integer.parseInt(st.nextToken());
}
br.close();
init(1, 0, N-1);
for (int i=0; i<tree.length; i++) {
System.out.println("tree[" + i + "] : " + tree[i]);
}
for (int i=0; i<M; i++) {
bw.write(query(1, 0, N-1, questions[i][0]-1, questions[i][1]-1)+"\n");
}
bw.flush();
bw.close();
}
}
인접 리스트는 그래프 이론에서 그래프를 표현하기 위한 방법 중 하나입니다. 그래프의 한 꼭짓점에서 연결되어 있는 꼭짓점들을 하나의 연결 리스트로 표현하는 방법입니다. 인접 행렬에 비하여 변이 희소한 그래프에 효율적 입니다.
동작방식
아래와 같은 그래프가 존재할때 인접행렬을 만들어 보겠습니다. 1노드에서 시작하여 2,3 노드로 연결됩니다. 그리고 3노드는 2,4 노드로 연결됩니다. 이는 단방향을 나타내고 있음을 알수 있습니다. 2차원 배열을 준비하고 배열의 Y축을 시작 좌표, 배열의 X축을 그래프가 향하는 노드라고 생각을하고 아래 그림과 같이 만들어 사용을 합니다.
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.Collections;
import java.util.PriorityQueue;
public class PriorityQueue_example_0 {
/**
* Priority Queue - Heap 으로 가장 많이 구현되어있다.
* - 먼저넣은 것중 우선순위가 높은 것을 뺀다.
* - 자료를 넣고 빼는 속도 모두 : logN
* - max, min 값 찾기에 많이 쓰임
*/
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException {
// min heap - 가장 위(0)가 가장 작은값
PriorityQueue<Integer> q = new PriorityQueue<Integer>();
q.add(5);
q.add(3);
q.add(7);
q.add(4);
q.add(5);
System.out.println(q.poll());
System.out.println(q.poll());
System.out.println(q.poll());
System.out.println(q.poll());
System.out.println(q.poll());
System.out.println(q.poll());
System.out.println("=======================");
// max heap - 가장 위(0)가 가장 큰값
PriorityQueue<Integer> qr = new PriorityQueue<Integer>(Collections.reverseOrder());
qr.add(5);
qr.add(3);
qr.add(7);
qr.add(4);
qr.add(5);
// 빼지않고, 가장 우선순위
System.out.println(qr.poll()); // 가장 큰 하나를 제거하고 출력
System.out.println(qr.poll()); // 가장 큰 하나를 제거하고 출력
System.out.println(qr.poll()); // 가장 큰 하나를 제거하고 출력
System.out.println(qr.poll()); // 가장 큰 하나를 제거하고 출력
System.out.println(qr.poll()); // 가장 큰 하나를 제거하고 출력
System.out.println(qr.poll()); // 가장 큰 하나를 제거하고 출력
// --> 힙소트
br.close();
bw.close();
}
}
이번에는 슬라이딩 윈도우 알고리즘과 DAT 자료구조를 이용한 간단한 문제를 풀어보겠습니다.
문제
입력된 문자열(알파벳)에서 길이가 M개의 구간에서 가장 많이 등장하는 알파벳을 출력하라
문자열 : "AAAABBBBAABKKKABKKKKDKAAA" M: 6
코드
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class SlidingWindow_DAT {
/**
* 슬라이등 윈도우 + DAT
*/
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException {
String str = "AAAABBBBAABKKKABKKKKDKAAA";
int n = str.length();
int m = 6;
int[] dat = new int[100];
//초기세팅 6개 DAT
char maxCh = ' ';
int maxCnt = 0;
for (int i = 0; i<m; i++) {
dat[str.charAt(i)]++;
if (dat[str.charAt(i)] > maxCnt) {
maxCnt = dat[str.charAt(i)];
maxCh = str.charAt(i);
}
}
//슬라이딩 윈도우
for (int i = 0; i<n - m; i++) {
//다음 준비
dat[str.charAt(i + m)]++;
dat[str.charAt(i)]--;
if (dat[str.charAt(i + m)] > maxCnt) {
maxCnt = dat[str.charAt(i + m)];
maxCh = str.charAt(i + m);
}
}
System.out.println(maxCh);
bw.close();
br.close();
}
}
풀이
dat 배열에 길이가 M인 구간에서 나타나는 알파벳을 카운트하여 줍니다. 문자열 AAAABBBBAABKKKABKKKKDKAAA에서 처음 AAAABB 를 확인하면 dat 배열 dat['A']는 4, dat['B'] 는 2가 들어갑니다. 그리고 다음으로 이동합니다. 슬라이딩 윈도우 알고리즘으로 길이가 6인 구간을 기준으로 뒤문자는 카운트를 더해주고, 앞문자는 카운트에서 빼줍니다. 작업이 완려되면 dat배열에 문자번째와 max변수를 비교하여 max변수를 갱신합니다. 이러한 방식으로 M구간에서 가장 많이 나오는 알파벳을 알아낼 수 있습니다.
슬라이딩 윈도우 알고리즘은 배열 요소의 일정 범위 값을 비교할때 사용하면 유용한 알고리즘 입니다.
동작방식
일정 정수로 이루어진 배열 int[] arr= {3,1,5,3,4,1,5,7,5,1,8} 가 있다면, 길이가 5인 배열의 합계가 가장 큰 것은 무엇인가? 라는 문제에 사용될 수 있습니다. 일반적으로 아래와 같이 0번째 부터 4번째 (길이가 5이므로) 합을 구하고 저장합니다. 그리고 1번째 부터 5번째까지의 합을 구하고 저장후 처음에 구했던 값과 비교를 하여 큰것을 가지고 있습니다. 이렇게 반복을 하면 됩니다. 하지만 이 방법은 매번 for 루프로 모든 배열의 요소를 지정된 길이만큼 순회하며 합계를 구해 최대값을 구해야하므로 비효율적 입니다.
이것을 간단히 생각해보면 처음에 해당 길이만큼 합계를 구하는 것은 어쩔수 없습니다. 하지만, 그 이후부터 매번 돌지 않고 인덱스 1~5까지의 합은 처음에 길했던 0~4까지의 합계에 0번째 배열의 값을 빼고, 5번째 배열의 값을 더한 값과 같습니다. 바로 이 부분에서 처음 구했던 0~4까지의 합계를 재사용하며 다음값을 구할 수 있는데, 이것이 슬라이딩 윈도우 알고리즘의 핵심입니다.
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class SlidingWindow_example {
static BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static int[] arr= {3,1,5,3,4,1,5,7,5,1,8};
static int n;
static int getFive(int index)
{
int sum= 0;
for (int i = 0; i<5; i++) {
sum += arr[i + index];
}
return sum;
}
public static void main(String[] args) throws IOException {
n = arr.length;
int max = -9999;
int sum = getFive(0);
for (int i = 0; i <= n - 5; i++) {
if (sum > max) max = sum;
// 마지막순간에는 다음 것을 준비할 필요 없음
if (i == n - 5) break;
// 다음 것을 준비
sum += arr[i + 5];
sum -= arr[i];
}
System.out.println(max);
bw.close();
br.close();
}
}
Vue 사용 웹 앱을 개발하기 위해 알아야하는 페이지 이동 방법을 알아보도록 하겠습니다. 페이지 이동방법은 뷰 라우터라는 것이 있습니다. 뷰 라우터는 뷰에서 라우팅 기능을 구현할 수 있도록 지원하는 공식 라이프러리입니다. 이것을 이용하면 뷰로 만든 페이지간 간에 자유로운 이동이 가능해 집니다.
[참고] 라우팅이란 ? 웹 페이지 간의 이동방법, 싱글 페이지 애플리케이션에서 주로 사용, 화면전환이 매끄러움, 사용자 접근성 향상
뷰 라우터를 구현하는 태그는 아래와 같습니다.
<script src="https://unpkg.com/vue-router/dist/vue-router.js"> : 라우터 라이브러리 <router-link to="URL 값"> : 페이지 이동 태그 <router-view> : 페이지 표시 태그
직접 아래 예제를 확인해 보도록 하겠습니다.
<!DOCTYPE html>
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Vue Router Sample</title>
</head>
<body>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
<script src="https://unpkg.com/vue-router/dist/vue-router.js"></script>
<div id="app">
<h1>뷰 라우터 샘플</h1>
<p>
<!-- 1 : URL 값을 변경하는 태그 -->
<router-link to="/foo">Foo 이동</router-link>
<router-link to="/bar">Bar 이동</router-link>
</p>
<!-- 2 : URL 값에 따라 갱신되는 화면 영역 -->
<router-view></router-view>
</div>
<script>
// 3 : 컴포넌트 정의
var Foo = { template: '<div>foo</div>'};
var Bar = { template: '<div>bar</div>'};
// 4 : 각 URL에 맞춰 표시할 컴포넌트 지정
var routes = [
{ path:'/foo', component:Foo },
{ path:'/bar', component:Bar }
];
// 5 : 뷰 라우터 정의
var router = new VueRouter({
routes
});
// 6 : 뷰 인스턴스에 라우터 추가
var app = new Vue({
router
}).$mount('#app');
</script>
</body>
</html>
아래는 실행 결과입니다.
뷰 기본 라우팅 방식을 이용하여 페이지를 전환하는 예제입니다.
<router-link>는 화면 상에서 <a> 버튼 태그로 변환되어 표시됩니다. to="" 정의된 텍스트 값이 브라우저 URL 끝에 추가됩니다.
<router-view>는 갱신된 URL에 해당하는 화면을 보여주는 영역입니다. 이곳에 나타낼 화면은 <script>에서 정의합니다.
Foo, Bar 컴포넌트에는 template 속성으로 각 컴포넌트를 구분할 수 있는 정도의 HTML 코드를 정의합니다.
routes 변수에는 URL 값이 /foo 일때 Foo 컴포넌트를, /bar 일때 Bar 컴포넌트를 표시하도록 정의합니다.
router 변수에는 뷰 라우터를 생성하고, routes 를 삽입해 URL에 따라 화면이 전환될 수 있게 정의합니다.
새 인스턴스를 생성하고 라우터의 정보가 담긴 router를 추가합니다.
$mount() API란? el 속성과 동일하게 인스턴스를 화면에 붙이는 역할을 합니다. 인스턴스를 생성할 때 el 속성을 넣지 않아도 $mount()를 이용하면 강제로 인스턴스르 화면에 붙일 수 있습니다.
기본 코드에서는 컴포넌트 1개만 표시되기 때문에 간단합니다. 하지만 실제 구현은 화면에 여러개의 컴포넌트로 분할된 경우가 많습니다. 그럼 여러 개의 컴포넌트를 동시에 표시할 수 있는 라우터인 네스티드 라우터와 네임드 뷰 라는 두가지가 있습니다.
네스티드 라우터
네스티드 라우터는 라우터로 페이지를 이동할 때 최소 2개 이상의 컴포넌트를 화면에 나타낼 수 있습니다. 상위 컴포넌트 1개에 하위컴포넌트 1개를 포함하는 구조로 구성됩니다. 아래와 같은 구조입니다.
<!DOCTYPE html>
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Vue Nested Router Sample</title>
</head>
<body>
<script src="https://unpkg.com/vue/dist/vue.js"></script>
<script src="https://unpkg.com/vue-router/dist/vue-router.js"></script>
<div id="app">
<p>
<router-link to="/user/foo">/user/foo</router-link>
<router-link to="/user/foo/profile">/user/foo/profile</router-link>
<router-link to="/user/foo/posts">/user/foo/posts</router-link>
</p>
<!-- 1 : User 컴포넌트가 뿌려질 영역 -->
<router-view></router-view>
</div>
<script>
// 2 : 컴포넌트의 내용 정의
var User = {
template: `
<div class="user">
<h2>User {{ $route.params.id }}</h2>
<router-view></router-view>
</div>
`
};
const UserHome = { template: '<div>Home</div>' };
const UserProfile = { template: '<div>Profile</div>' };
const UserPosts = { template: '<div>Posts</div>' };
// 3 : 네스티드 라우팅 정의
var routes = [
{ path: '/user/:id', component: User,
children: [
// UserHome will be rendered inside User's <router-view>
// when /user/:id is matched
{ path: '', component: UserHome },
// UserProfile will be rendered inside User's <router-view>
// when /user/:id/profile is matched
{ path: 'profile', component: UserProfile },
// UserPosts will be rendered inside User's <router-view>
// when /user/:id/posts is matched
{ path: 'posts', component: UserPosts }
]
}
];
// 4 : 뷰 라우터 정의
var router = new VueRouter({
routes
});
// 5 : 뷰 인스턴스에 라우터 추가
var app = new Vue({ router }).$mount('#app')
</script>
</body>
</html>
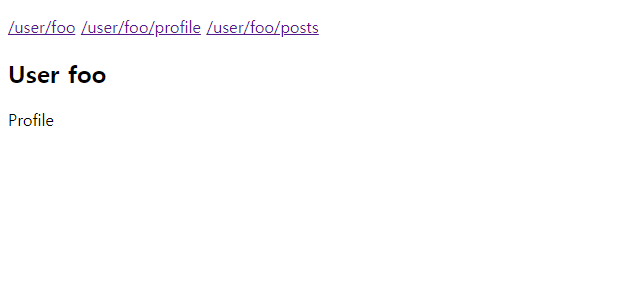
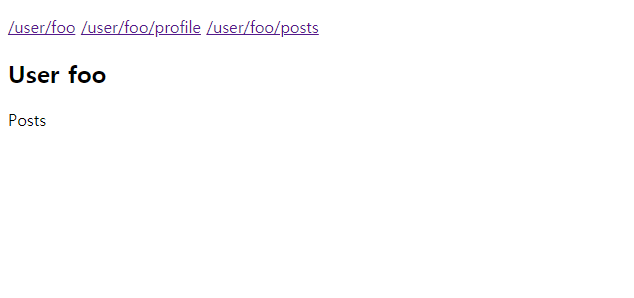
아래는 실행 결과 입니다.
User 컴포넌트를 상위 컴포넌트로 놓고 URL에 따라 각각의 컴포넌트를 표시하는 코드입니다. 네스티드 라우터와 기본 라우터의 차이점은 최상위 컴포넌드에도 <router-view>가 있고, 최상위 컴포넌트의 하위 컴포넌트(User)에도 <router-view>가 있다는 것 입니다. 네스티드 라우터는 화면을 구성하는 컴포넌트의 수가 적을 때는 유용하지만 많은 컴포넌트를 표시하는데는 한계가 있습니다. 이것을 해결할 수 있는 방안이 네임드 뷰입니다.
네임드 뷰
네임드 뷰는 특정 페이지로 이동했을 때 여러 개의 컴포넌트를 동시에 표시하는 라우팅 방식입니다. 네스티드 라우터 방식은 상위 컴포넌트가 하위 컴포넌트를 포함하는 형식이지만, 네임드 뷰는 같은 레벨에서 여러 개의 컴포넌트를 한 번에 표시합니다.
<!DOCTYPE html>
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Vue Named View Sample</title>
</head>
<body>
<script src="https://unpkg.com/vue/dist/vue.js"></script>
<script src="https://unpkg.com/vue-router/dist/vue-router.js"></script>
<!-- 1 : 라우팅 영역 정의 -->
<div id="app">
<router-view name="header"></router-view>
<router-view></router-view>
<router-view name="footer"></router-view>
</div>
<script>
// 2 : 컴포넌트의 내용 정의
var Body = { template: '<div>This is Body</div>'};
var Header = { template: '<div>This is Header</div>'};
var Footer = { template: '<div>This is Footer</div>'};
// 3 : 네스티드 라우팅 정의
var routes = [
{ path: '/', components: {
default : Body,
header : Header,
footer : Footer
}
}
];
// 4 : 뷰 라우터 정의
var router = new VueRouter({
routes
});
// 5 : 뷰 인스턴스에 라우터 추가
var app = new Vue({ router }).$mount('#app')
</script>
</body>
</html>
아래는 실행 결과 입니다.
위 코드를 실행하면 URL 값 '/'에 의해 네임드 뷰가 바로 실행됩니다. 코드를 살펴보면 아래와 같습니다.
<router-view>에 name 속성을 추가하는데 name 속성은 아래 components 속성에 정의하는 컴포넌트와 매칭하기 위한 속성입니다. name 속성이 없는 것은 default로 표시될 컴포넌트를 의미합니다.
Body, Header, Footer 컴포넌트의 내용에 담길 객체를 선언합니다.
라우팅정보를 정의합니다.
뷰 라우터를 정의합니다.
뷰 인스턴스에 라우터를 추가합니다.
네임드 뷰를 활용하면 특정 페이지로 이동했을 때 해당 URL에 맞추어 여러 개의 컴포넌트를 한 번에 표시할 수 있습니다.